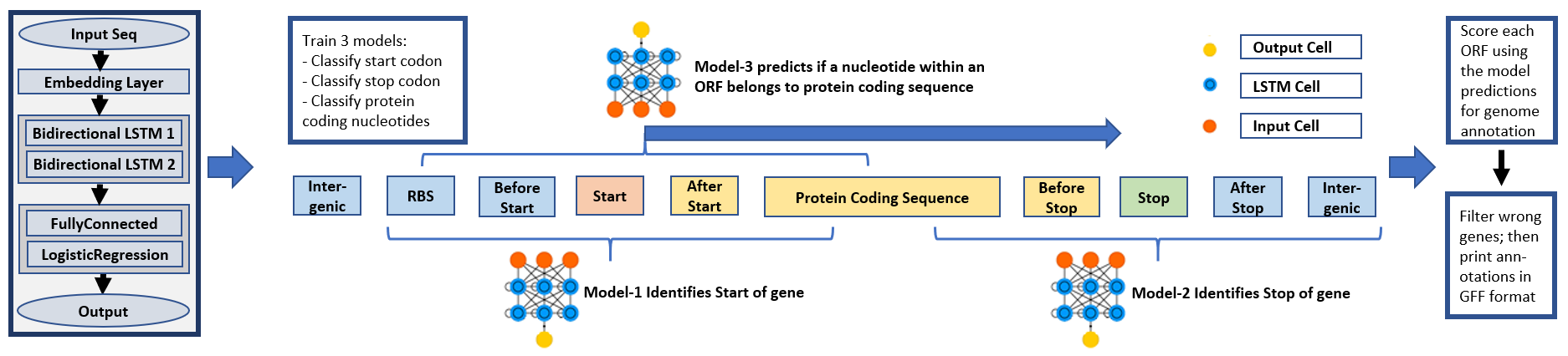
 Genome Annotation with Deep Learning
Genome Annotation with Deep Learning
Bengali word embeddings and it's application in solving document classification problem
Abstract
In this paper, we present Bengali word embeddings and it’s application in the classification of news documents. Word embeddings are multi-dimensional vectors that can be created by exploiting the linguistic context of the words in large corpus. To generate the embeddings, we collected Bengali news document of last five years from the major daily newspapers. Word embeddings are generated using the Neural Network based language processing model Word2vec. We use the vector representations of the Bengali words to cluster them using K-means algorithm. We show that those clusters can be used directly to perform various natural language processing task by solving the problem of Bengali news document classification. We use the Support Vector Machine (SVM) for the classification task and achieve ~91% F1-score. The accuracy of our method demonstrates that our word embeddings could capture the semantics of word from the respective context correctly.